WORK IN PROGRESS
User Guides - Data Producers
Welcome to the User Guide section of the Data Marketplace! This section is specifically designed for data owners or data stewards looking to publish their data products & data contracts. Here, you will find detailed instructions about how to get onboarded to the Data Marketplace, as well as how to publish your data products & data contracts.
1. How to create a Data Product Team on the Data Marketplace?
What is Domain Team/Data Product Team?
Domain teams take ownership of data assets belonging to a specific domain and ensure they are up to date and complete.
Every organization in NNDM consists of a domain team, which owns all the data products that are always associated with a source system.
Note: The option mentioned below is visible only when you have "super-admin" access.
Steps to Create a Data Product Team (Domain Team) in NNDM
Navigate to the NNDM Service: NNDM Service
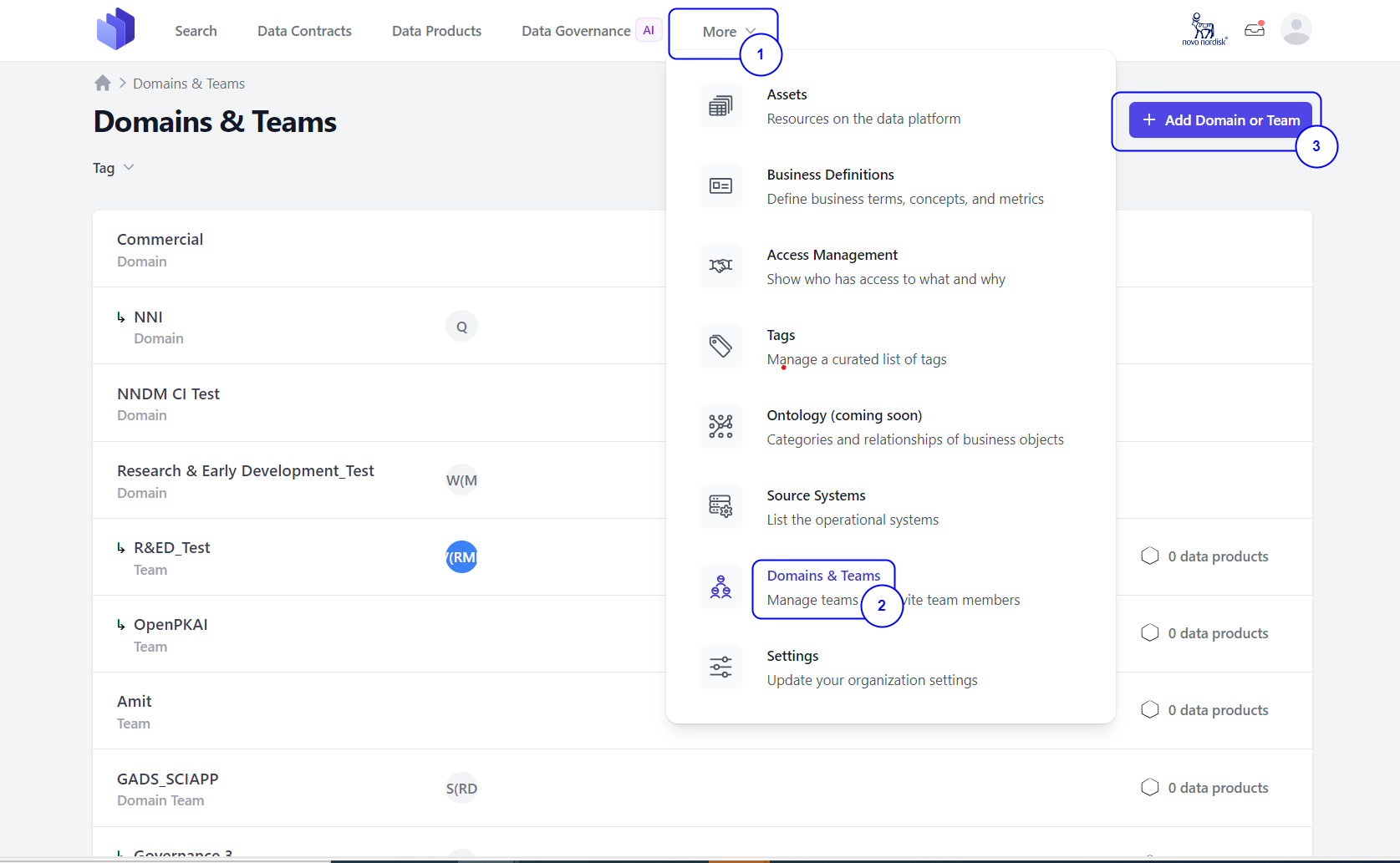
Step 1: Click on the More drop-down button from the UI.
Step 2: Click on the Domains & Teams option.
Step 3: Click on the Add Domain or Team button.
Step 4: Providing all the necessary information as mentioned below:
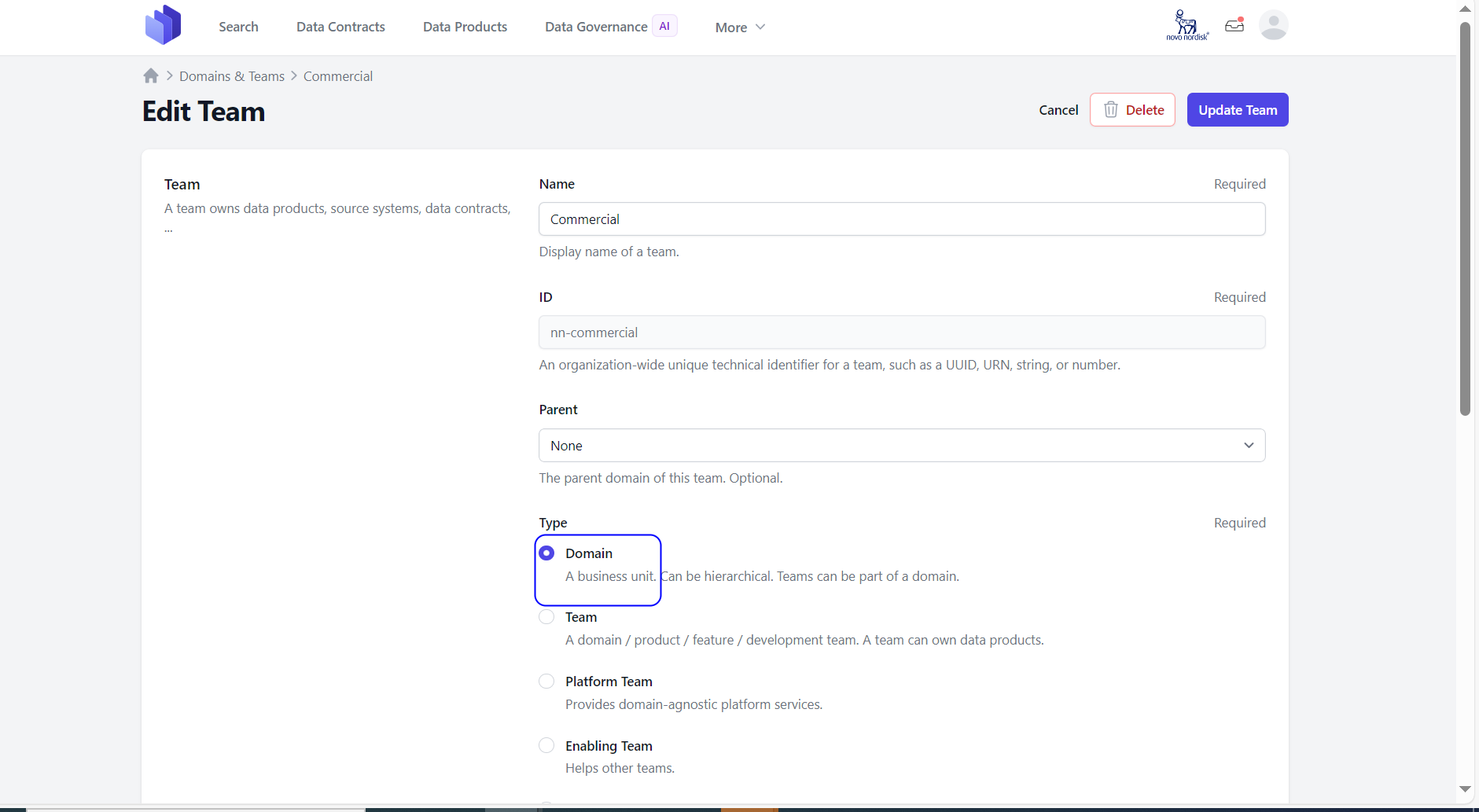
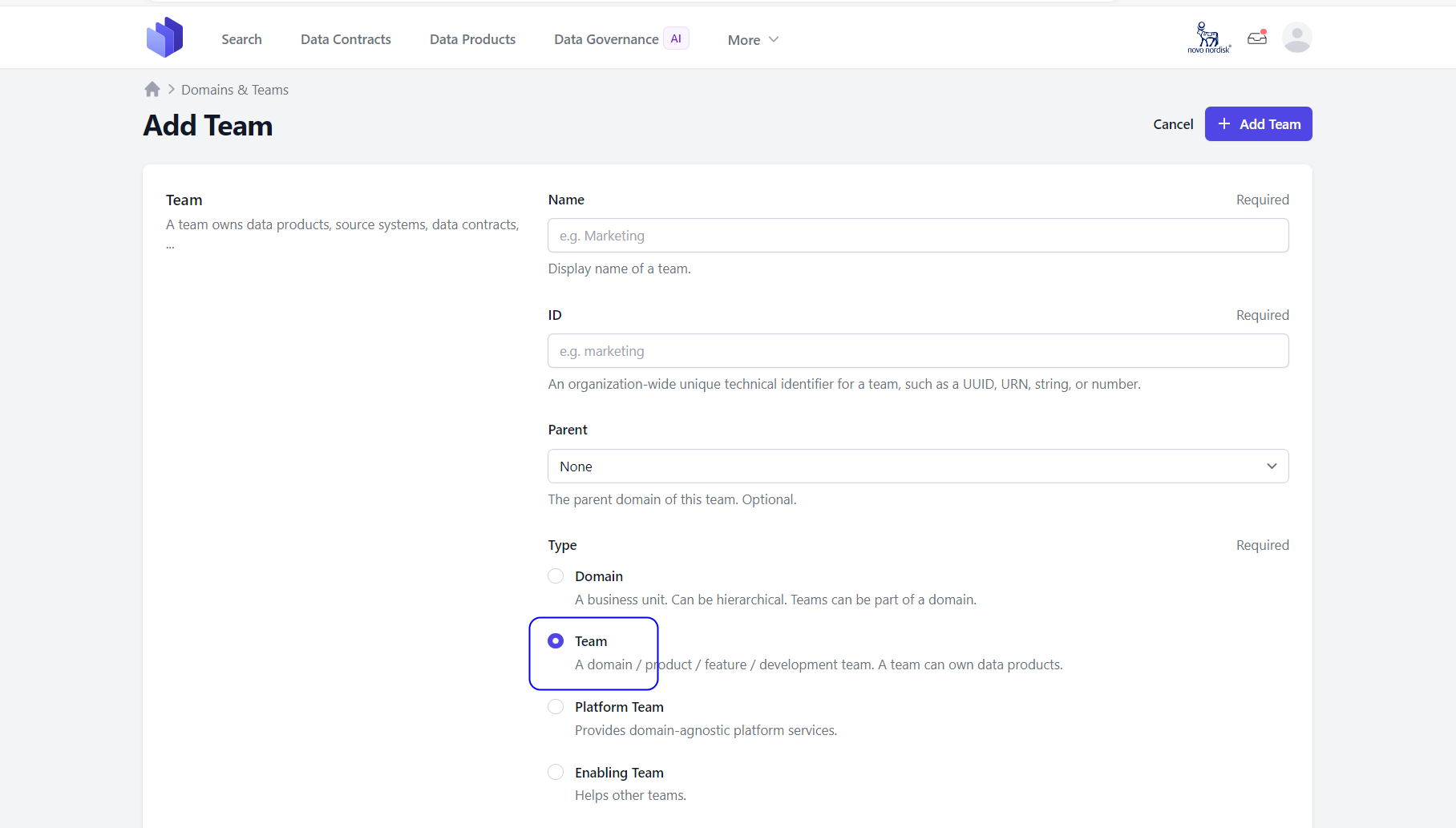
Fields and attributes to create a domain teams: * Name – The display name of this group. (Required Field)
- ID - An organization-wide unique technical identifier for this group, such as a UUID, URN, slug, or number. (Required Field)
- Parent - Choose any of the following options: Domain, Team, or Governance Group.
- Type - Select any of the following options: Domain, Team, or Governance Group.
- Tags - Tags are labels or keywords assigned to items such as domains, teams, data products, or any other entities within the NNDM system. These tags help in organizing, categorizing, and easily retrieving relevant information.
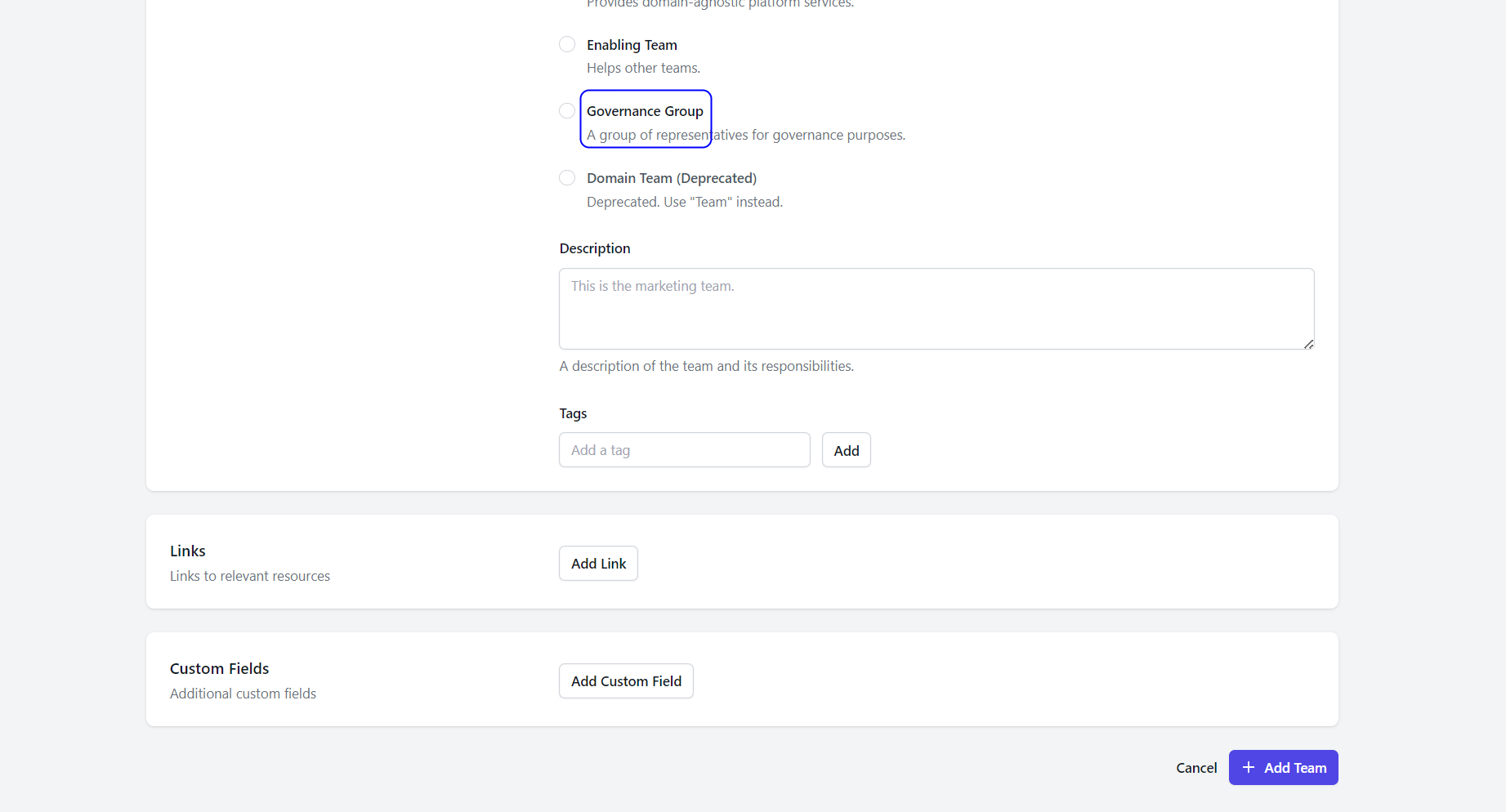
- Description – Description of the group.
- Custom Fields: Additional custom fields. Key value pair – Name and Value
- Links -Links are references or connections to other resources, documents, or web pages that provide additional information or context.
4.1: If user is creating a Domain group:
4.2: If user is creating a Team group:
4.3: If user is creating a Governance group:
Once all the necessary information is field click on ADD TEAM button.
Step 5: Once the Domain or Team is created in the NNDM UI, users can add a subdomain or subteam if needed by clicking on the Add Subdomain or Subteam located on the right-hand side of the UI.
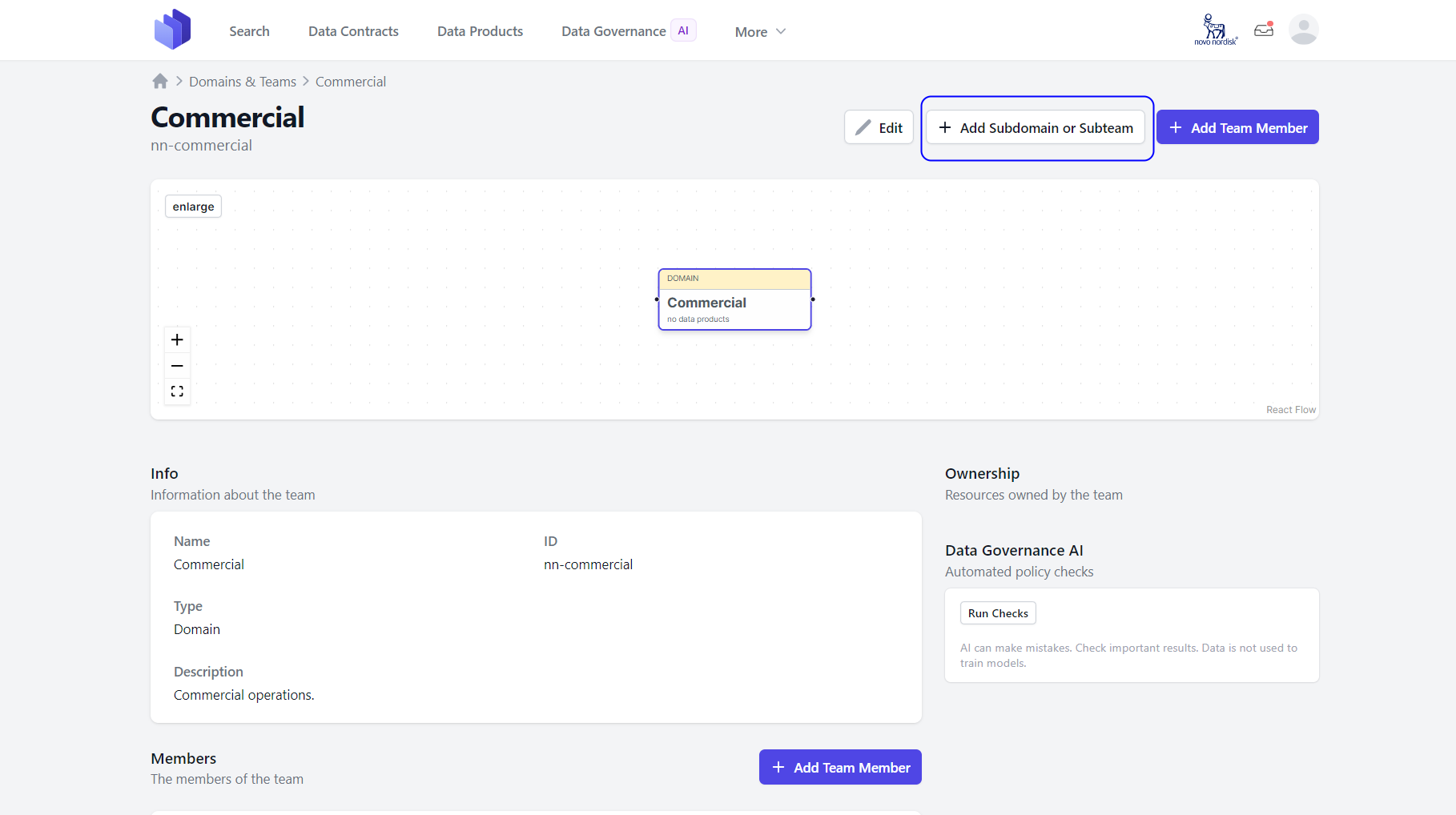
Step 6: The Data Product Owner can now add new team members by clicking on the Add Team Member button located on the right-hand side.
Finally, the domain team and new members can be viewed under the Domain & Team using the More menu.
2. How to publish Data Product(s) & Data Contract(s) via the Data Marketplace CI Tool
What is the NNDM CI Tool?
Capturing or onboarding the Data Product(s) & Contract(s) via the CI tool created by the NNDM Team, has the following benefits: * Built-in artefact ID generation that is in a form of a governed uniform resource name (for source systems, teams, products and contracts) * Single pipeline to upload multiple products and associated contracts * Pluggable to existing repository that contains data contracts within a folder * Validates Data Product and Data Contract inputs * Docker image can be used to run it locally.
Artefacts
NNDM CI Tool Repository * Git repository to see a working example of the CI tool, as well to import the documents into ones own repository
Data Contract YAML (Template) (TODO: Add link) * Template for a standard Data Contract which can be used as a starting point
Config.toml file (Template) (TODO: Add link) * Configuration file template that defines the related source system, the Data Product Team, as well as the Data Product(s) Specification(s).
Pipeline.yaml (CI Tool) (TODO: Add link) * Example of a pipeline that includes a step using the CI Tool to do the following actions in the backend: * Create Data Product(s) & Data Contract(s) for the defined team * Onboard & associate the specified Source System * Check for duplicate contracts
API Key * API Key for a specific Data Product Team, which is created in NNDM by an ADMIN, and then shared to the Data Product Team in a safe manner
Prerequisites
- Source System is registered in ServiceNow (ex. Snowflake) and was onboarded to NNDM by NNDM Tech Team
- Data Product Team is created & their unique API key is created & communicated by NNDM Team
- Repository is created and owned by LoB
Steps to to capture Data Product(s) & Data Contract(s) in NNDM via the NNDM CI Tool
Step 1. Fill out Data Contract YAML files with all relevant information based on the Data Contract YAML (Template) and store them in a folder in your repository
Step 2. Import/Copy the Config.toml file (Template) into the root your repository and fill it out with the Source System ServiceNow ID, NNDM Data Product Team ID, data contract folder name(s), and specifications of the Data Product(s)
Step 3. Copy the pipeline into your repository or add it as a step in your existing pipeline
Step 4. Configure the required variables for the pipeline * NNDM_INSTANCE - Target instance of NNDM to which the product and contracts should be uploaded. * DEV, TEST, VAL, or PROD * NNDM_API_KEY - The generated API key from the onboarding for data product team * NNDM_CONFIG_FILE_PATH - Name of the Config.toml file
Step 5. Wait for Admin in NNDM Team to accept service connection to Docker Container part of the pipeline (one-time occurence)
Config.toml - Fields and Attributes
- sourceID (required) - ServiceNow ID for the source system associated with the Data Product(s). This is an integer of up to 7 digits. Ex. 'sourceId=123456'. The source system should already be onboarded by NNDM Team
- teamID (required) - NN Data Marketplace Team ID for the Data Product Team associated with the Data Product(s). This is a literal. Ex. 'urn:team:platform:NNDM(domain:test)'
- productId (required) - Data Product ID that is created on the NN Data Marketplace when using the CI Tool. This should be the internal ID that is assigned for the product. "Ex. 'urn:data:product:001234'
- productName (required) - Data Product Name. Can be a literal. Ex. "OpenPKai"
- productDescription (required) - Data Product Description. HTML tags are supported. Can be a multi-line string. Ex. """The Data Product for PK data aims to facilitate: Better understanding of features important for PK for faster decision making in research projects Reduced number of compound design cycles based on animal studies (#500 days aspiration) Enable machine learning in research projects Reduced #animal studies Faster extraction of PK information & deliverables of PK analysis results to research projects."""
- productStatus (required) - Data Product Status. Should be one of proposed, in-development, active, or retired.
- proposed: Represents a data product in planning state
- in-development: Represents a data product actively being developed
- active: Represents a data product which is active and available
- retired: Represents a data product which was active but currently has been retired and is no longer available
- productArchetype (required) - Data Product Archetype. Should be one of consumer-aligned, aggregate, or source-aligned.
- source-aligned: Represents the data as it is in the operational system with minimal transformation. I am seeing organizations use these as a first step to creating more valuable data products.
- aggregate: Represents the data that has been aggregated from multiple sources. These are often used to create more complex data products by combining data from different sources. TL;DR definition of aggregate data products is that they’re built at a corporate level to drive global KPIs.
- consumer-aligned: Represents the data that has been transformed into a format that is useful for consumers of the data. These are often used in BI and analytics solutions. When ‘data products’ are referred to generically — these are the data products that people think about and discuss most.
- productMaturity (required) - Data Product Maturity. Should be one of raw, defined, or managed.
- raw: This represents a data product that is under data exploring maturity and is not capitalizing on the data product's full potential.
- defined: This represents a data product that has been refined, cleaned, and validated to be ready for consumption by consumers of the data.
- managed: This represents a data product that is managed and is a data-transformed product.
- rootContract (required) - Relative path to the Folder, which contains all Data Contracts (YAML or JSON) associated with this Data Product. Is a literal. Ex. './p1contracts'
- contractRequiredFields - Additional required fields in addition to ODCSv3.0.0 that should be enforced for this Data Product. This is an array. Ex. ['name1', 'name2']
- flagSchemaDrift - Boolean that indicates if schema drift should be monitored or not for this data product. This is typically set to false unless there are specific concerns about schema changes affecting consumers of the data. Ex. false
- if set to false this will not throw a warning on the pipeline run if schema changes occur to any associated contract within the data product
- if set to true this will throw a warning on the pipeline run if schema changes occur to any associated contract within the data product
- rootInfra - Literal that contains the relative path to the infrastructure configuration file that is used by the product ETL. Ex. './infra'
- rootAgreement - Absolute or relative path to the folder containing all usage agreements (IA) related to the data contracts in this data product. Ex. './agreements'
- productTags - Data Product Tags. Array of strings. Currently this is not connected to tags-as-a-service. Ex. ['tag1','tag2']
Data Contract - Fields and Attributes
- Title – The display name of this data contract. (Required Field)
- ID - An organization-wide unique technical identifier for this data contract, such as a UUID, URN, slug, or number. (Required Field)
- Version - The version of the data contract document (which is distinct from the Data Contract Specification version). (Required Field)
- Status – Proposed, In development, Active, Depreciated and Retired
- Description – Description of the Data Contract
- Owner - The team responsible for managing the data contract. Only your teams are displayed. (Required Field)
- Contact Name - The identifying name of the contact person/organization.
- Contact URL - The URL pointing to the contact information. This MUST be in the form of a URL.
- Contact Email - The email address of the contact person/organization. This MUST be in the form of an email address.
- Server: Information about the servers.
- Server – Server name /url
- Server Type – Type of server like S3 or Snowflake
- Terms : Terms and conditions for access
- Usage - The usage terms for this data contract.
- Limitations - Limitations of the usage of this data contract.
- Billing - Costs associated with the usage data contract.
- Notice Period - The notice period for consumers in ISO 8601 period format, e.g., P3M for 3 months.
- Model: The logical data model.
- Model – The name of the model, e.g., the table name
- Title - The title, e.g., the business name
- Type – Table, Message, Object and Graph
- Description – Description of the model
- Fields - Field Name
- Type – Data Type like string, int, varchar ,text
- Semantic Description - Semantic Description
- Example: Example data like Type, model, description and data
- Service Levels: A service level an agreed measurable level of performance for provided the data.
- Availability - The promise or guarantee by the service provider about the uptime of the system that provides the data.
- Description - An optional string describing the availability service level.
- Percentage - An optional string describing the guaranteed uptime in percent (e.g., 99.9%)
- Retention - The period how long data will be available.
- Description - An optional string describing the retention service level.
- Period - An optional period of time, how long data is available. Supported formats: Simple duration (e.g., 1 year, 30d) and ISO 8601 duration (e.g, P1Y).
- Unlimited - An optional indicator that data is kept forever.
- Timestamp Field - An optional reference to the field that contains the timestamp that the period refers to.
- Latency - The maximum amount of time from the source to its destination.
- Description - An optional string describing the latency service level.
- Threshold - An optional maximum duration between the source timestamp and the processed timestamp. Supported formats: Simple duration (e.g., 24 hours, 5s) and ISO 8601 duration (e.g, PT24H).
- Source Timestamp Field - An optional reference to the field that contains the timestamp when the data was provided at the source.
- Processed Timestamp Field - An optional reference to the field that contains the processing timestamp, which denotes when the data is made available to consumers of this data contract.
- Freshness - The maximum age of the youngest entry.
- Description - An optional string describing the freshness service level.
- Threshold - An optional maximum age of the youngest entry. Supported formats: Simple duration (e.g., 24 hours, 5s) and ISO 8601 duration (e.g, PT24H).
- Timestamp Field - An optional reference to the field that contains the timestamp that the threshold refers to.
- Frequency - How often data is updated.
- Description - An optional string describing the frequency service level.
- Type - An optional type of data processing. Typical values are batch, micro-batching, streaming, manual.
- Interval - Optional. Only for batch: How often the pipeline is triggered, e.g., daily.
- Cron - Optional. Only for batch: A cron expression when the pipelines is triggered. E.g., 0 0 * * *.
- Support - The times when support is provided.
- Description - An optional string describing the support service level.
- Time - An optional string describing the times when support will be available for contact such as 24/7 or business hours only.
- Response Time - An optional string describing the time it takes for the support team to acknowledge a request. This does not mean the issue will be resolved immediately, but it assures users that their request has been received and will be dealt with.
- Backup - Details about data backup procedures.
- Description – An optional string describing the backup service level.
- Interval - An optional interval that defines how often data will be backed up, e.g., daily.
- Cron – An optional cron expression when data will be backed up, e.g., 0 0 * * *.
- Recovery Time – An optional Recovery Time Objective (RTO) specifies the maximum amount of time allowed to restore data from a backup after a failure or loss event (e.g., 4 hours, 24 hours).
- Recovery Point - An optional Recovery Point Objective (RPO) defines the maximum acceptable age of files that must be recovered from backup storage for normal operations to resume after a disaster or data loss event. This essentially measures how much data you can afford to lose, measured in time (e.g., 4 hours, 24 hours).
- Custom Fields: Additional custom fields. Key value pair – Name and Value
How to Publish Data Product(s) & Data Contract(s) via the Data Marketplace UI
How to create a Data Product
What is a Data Product?
A data product is a logical unit that contains all components to process and store domain data for analytical or data-intensive use cases and makes them available to other teams via output ports. You can think of a module or microservice, but for analytical data.
Data products connect to sources, such as operational systems or other data products and perform data transformation. Data products serve data sets in one or many output ports. Output ports are typically structured data sets, as defined by a data contract.
A data product is owned by a domain team. The team is responsible for the operations of the data product during its entire lifecycle. The team needs to continuously monitor and ensure data quality, availability, and costs.
Steps to Create a Data Product in NNDM
Navigate to the NNDM Service: https://marketplace.nndm.pub.azure.novonordisk.com/
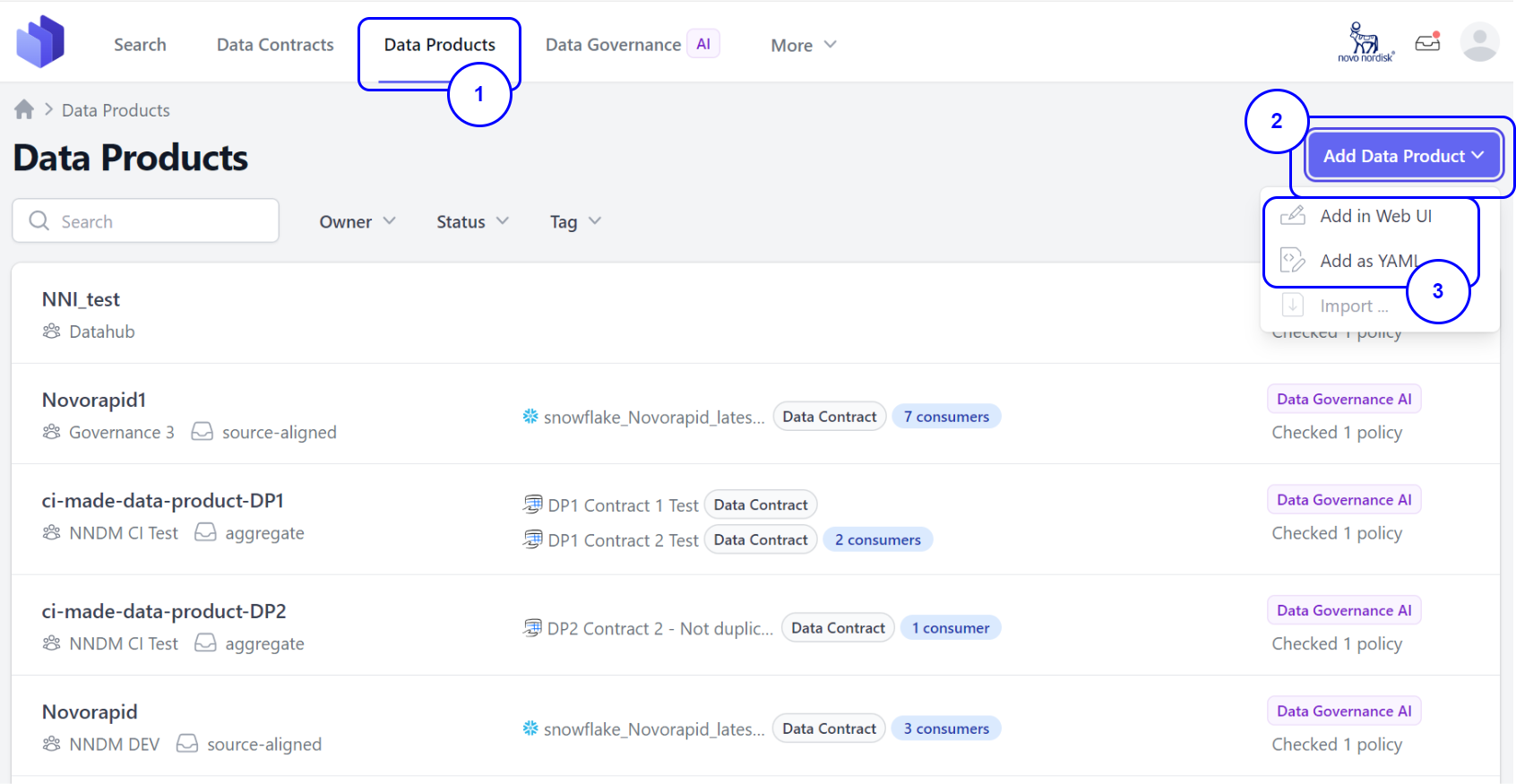
Step 1. Go to the Data Product tab from the UI. Step 2. Click on the Add Data Product button located on the right-hand side. Step 3. You will see two options: 3.1 Add in Web UI: Manually add the product by providing all necessary information.
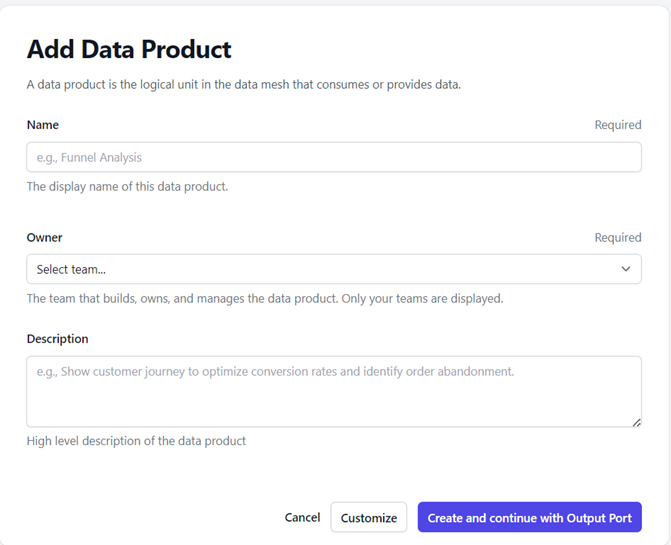 Fields and Attributes to create a Data Product:
* Title: The display name of the data product. (Required)
* ID: An organization-wide unique technical identifier for this data product, such as a UUID, URN, slug, or number. (Required)
* Owner: The team that builds, owns and manages the data product. (Required)
* Status: Proposed, In development, Active, Depreciated and Retired
* Archetype: The classification of domain data- source-aligned, aggregate, consumer-aligned
* Maturity: The level of stability, reliability, data quality and support for use in production
* Description: The description of the data product
* Tags: Add tags that are relevant to the data product
* Links: Links to relevant sources
* Custom Fields: Additional custom fields. Key value pair – Name and Value
Fields and Attributes to create a Data Product:
* Title: The display name of the data product. (Required)
* ID: An organization-wide unique technical identifier for this data product, such as a UUID, URN, slug, or number. (Required)
* Owner: The team that builds, owns and manages the data product. (Required)
* Status: Proposed, In development, Active, Depreciated and Retired
* Archetype: The classification of domain data- source-aligned, aggregate, consumer-aligned
* Maturity: The level of stability, reliability, data quality and support for use in production
* Description: The description of the data product
* Tags: Add tags that are relevant to the data product
* Links: Links to relevant sources
* Custom Fields: Additional custom fields. Key value pair – Name and Value
3.2 Add as YAML: Upload a data product as a .yaml file. For example:
Refer Sample Here: Sample Data Product - Overview
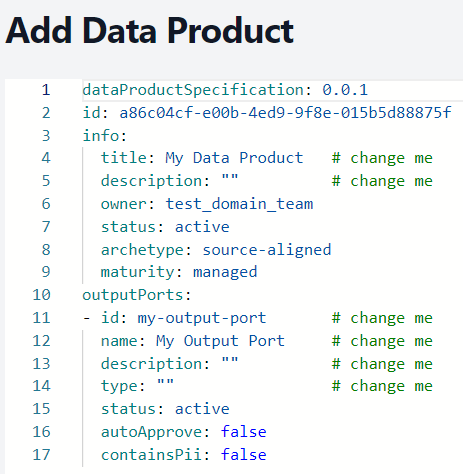
After completing this, click on Add Data Product. The new data product will now be visible under the Data Product tab.
How to create a Data Contract
What is a Data Contract?
A data contract is a document that defines the structure, format, semantics, quality, and terms of use for exchanging data between a data provider and their consumers. It covers: - Data Product Provider, including owner and the output port to access - Terms and conditions of data usage - Schema and semantics of provided data attributes - Quality attributes, such as freshness and number of rows - Service-level objectives, such as availability and support times
While a data contract represents the interface specification, the actual implementation that provides the data is the output port of a data product.
Data contracts come into play when data is exchanged between different teams or organizational units. First and foremost, data contracts are a communication tool to express a common understanding of how data should be structured and interpreted.
They make semantic and quality expectations explicit. Later in development and production, they also serve as the basis for code generation, testing, schema validations, quality checks, monitoring, access control, and computational governance policies. Data contracts can also be used for the input port for consumer-driven contract testing to verify that the data is provided as specified.
Steps to Create a Data Contract in NNDM
Navigate to the NNDM Service. : https://marketplace.nndm.pub.azure.novonordisk.com/
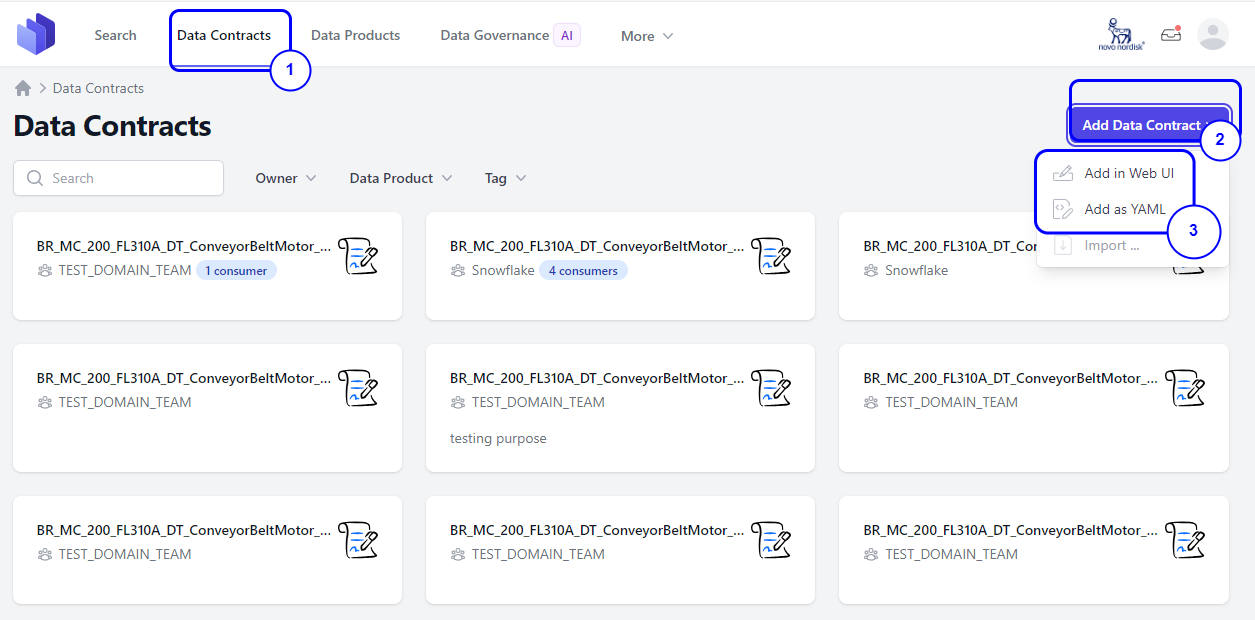
Step 1. Go to the Data Contract tab from the UI. Step 2. Click on the Add Data Contract button located on the right-hand side. Step 3. You will see two options:
3.1 Add in Web UI: Manually add the contract by providing all necessary information.
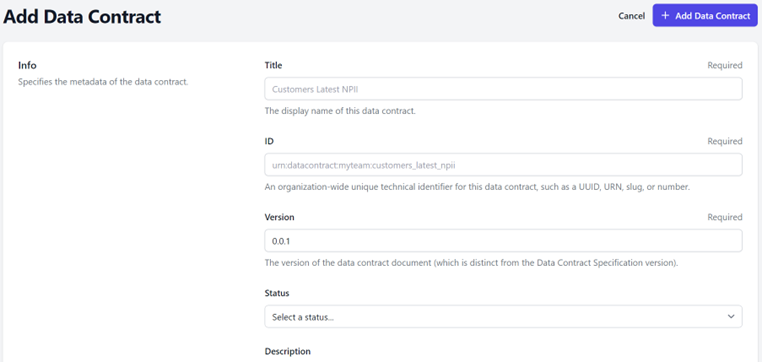
Fields and Attributes to create a Data Contract:
-
Title – The display name of this data contract. (Required Field)
-
ID - An organization-wide unique technical identifier for this data contract, such as a UUID, URN, slug, or number. (Required Field)
-
Version - The version of the data contract document (which is distinct from the Data Contract Specification version). (Required Field)
-
Status – Proposed, In development, Active, Depreciated and Retired
-
Description – Description of the Data Contract
-
Owner - The team responsible for managing the data contract. Only your teams are displayed. (Required Field)
-
Contact Name - The identifying name of the contact person/organization.
-
Contact URL - The URL pointing to the contact information. This MUST be in the form of a URL.
-
Contact Email - The email address of the contact person/organization. This MUST be in the form of an email address.
-
Server: Information about the servers.
- Server – Server name /url
- Server Type – Type of server like S3 or Snowflake
- Terms : Terms and conditions for access
- Usage - The usage terms for this data contract.
- Limitations - Limitations of the usage of this data contract.
- Billing - Costs associated with the usage data contract.
- Notice Period - The notice period for consumers in ISO 8601 period format, e.g., P3M for 3 months.
- Model: The logical data model.
- Model – The name of the model, e.g., the table name
- Title - The title, e.g., the business name
- Type – Table, Message, Object and Graph
- Description – Description of the model
- Fields - Field Name
- Type – Data Type like string, int, varchar ,text
- Semantic Description - Semantic Description
- Example: Example data like Type, model, description and data
- Service Levels: A service level an agreed measurable level of performance for provided the data.
- Availability - The promise or guarantee by the service provider about the uptime of the system that provides the data.
- Description - An optional string describing the availability service level.
- Percentage - An optional string describing the guaranteed uptime in percent (e.g., 99.9%)
- Retention - The period how long data will be available.
- Description - An optional string describing the retention service level.
- Period - An optional period of time, how long data is available. Supported formats: Simple duration (e.g., 1 year, 30d) and ISO 8601 duration (e.g, P1Y).
- Unlimited - An optional indicator that data is kept forever.
- Timestamp Field - An optional reference to the field that contains the timestamp that the period refers to.
- Latency - The maximum amount of time from the source to its destination.
- Description - An optional string describing the latency service level.
- Threshold - An optional maximum duration between the source timestamp and the processed timestamp. Supported formats: Simple duration (e.g., 24 hours, 5s) and ISO 8601 duration (e.g, PT24H).
- Source Timestamp Field - An optional reference to the field that contains the timestamp when the data was provided at the source.
- Processed Timestamp Field - An optional reference to the field that contains the processing timestamp, which denotes when the data is made available to consumers of this data contract.
- Freshness - The maximum age of the youngest entry.
- Description - An optional string describing the freshness service level.
- Threshold - An optional maximum age of the youngest entry. Supported formats: Simple duration (e.g., 24 hours, 5s) and ISO 8601 duration (e.g, PT24H).
- Timestamp Field - An optional reference to the field that contains the timestamp that the threshold refers to.
- Frequency - How often data is updated.
- Description - An optional string describing the frequency service level.
- Type - An optional type of data processing. Typical values are batch, micro-batching, streaming, manual.
- Interval - Optional. Only for batch: How often the pipeline is triggered, e.g., daily.
- Cron - Optional. Only for batch: A cron expression when the pipelines is triggered. E.g., 0 0 * * *.
- Support - The times when support is provided.
- Description - An optional string describing the support service level.
- Time - An optional string describing the times when support will be available for contact such as 24/7 or business hours only.
- Response Time - An optional string describing the time it takes for the support team to acknowledge a request. This does not mean the issue will be resolved immediately, but it assures users that their request has been received and will be dealt with.
- Backup - Details about data backup procedures.
- Description – An optional string describing the backup service level.
- Interval - An optional interval that defines how often data will be backed up, e.g., daily.
- Cron – An optional cron expression when data will be backed up, e.g., 0 0 * * *.
- Recovery Time – An optional Recovery Time Objective (RTO) specifies the maximum amount of time allowed to restore data from a backup after a failure or loss event (e.g., 4 hours, 24 hours).
- Recovery Point - An optional Recovery Point Objective (RPO) defines the maximum acceptable age of files that must be recovered from backup storage for normal operations to resume after a disaster or data loss event. This essentially measures how much data you can afford to lose, measured in time (e.g., 4 hours, 24 hours).
- Custom Fields: Additional custom fields. Key value pair – Name and Value
3.2 Add as YAML: Upload a data contract as a .yaml file. For example:
Refer Sample here: Sample Data Contract - Overview
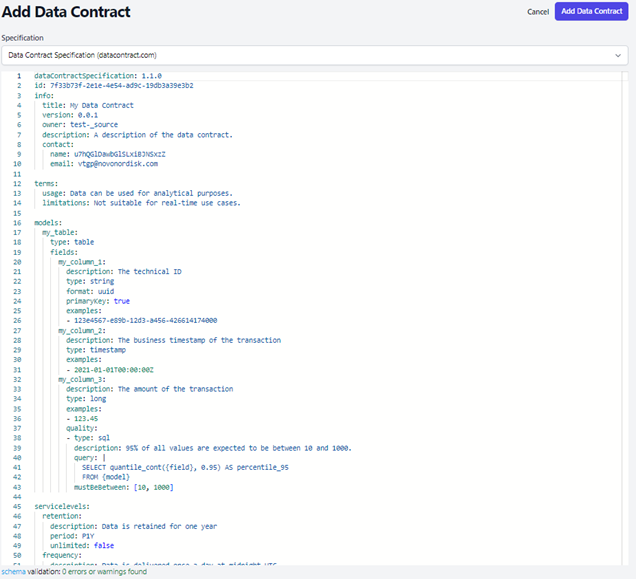
After completing this, click on Add Data Contract. The new data contract will now be visible under the Data Contract tab.